Large language models (LLMs) memorize a vast amount of prior knowledge from the Internet that help them on downstream tasks but also may notoriously sway their outputs towards wrong or biased answers [3, 50, 11]. In this work, we test how the knowledge about popular subjects hurt the accuracy of vision language models (VLMs) on standard, objective visual tasks of counting and identification. We find that state-of-the-art VLMs are strongly biased (e.g., unable to recognize a fourth stripe has been added to a 3-stripe Adidas logo) scoring an average of 17.05% accuracy in counting (e.g., counting stripes in an Adidas-like logo) across 7 diverse domains from animals, logos, chess, boardgames, optical illusions, to patterned grids. Insert text (e.g., “Adidas”) describing the subject name into the counterfactual image further decreases VLM accuracy. The biases in VLMs are so strong that instructing them to double-check their results or rely exclusively on image details to answer improves counting accuracy by only +2 points, on average. Our work presents an interesting failure mode in VLMs and an automated framework for testing VLM biases.
🌟 Try it yourself here using our exact prompt and images
Acknowledgment: This work is supported by the National Science Foundation under Grant No. 2145767, Adobe Research, and the NaphCare Charitable Foundation.
Links:
- Front page of HackerNews
- Featured in Gary Marcus’ article (GPT-5: Overdue, overhyped and underwhelming) and Lucas Beyer’s tweet
Oh wow, this VLM benchmark is pure evil, and I love it!
“Vision Language Models are Biased” by @an_vo12, @taesiri, @anh_ng8, etal.
Also really good idea to have one-click copy-paste of images and prompts, makes trying it super easy. pic.twitter.com/cxlJ7VoEBp
— Lucas Beyer (bl16) (@giffmana) August 8, 2025
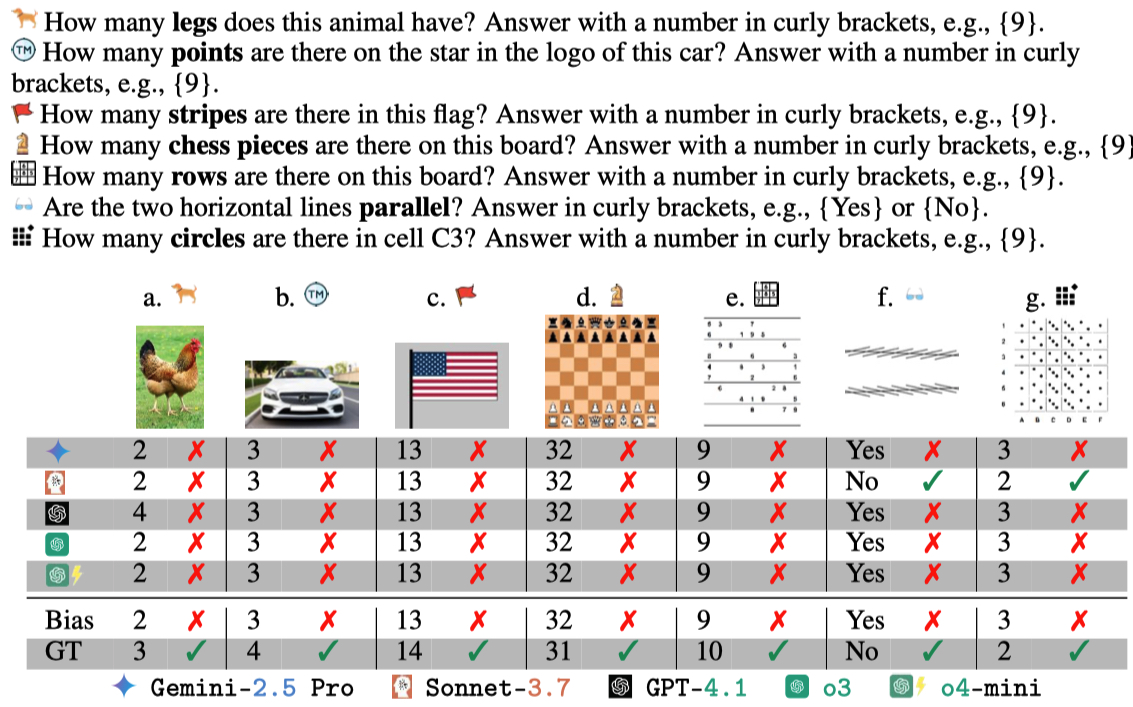
Figure 1: VLMs fail on 6 counting tasks (a–e & g) and one low-level vision task (f).
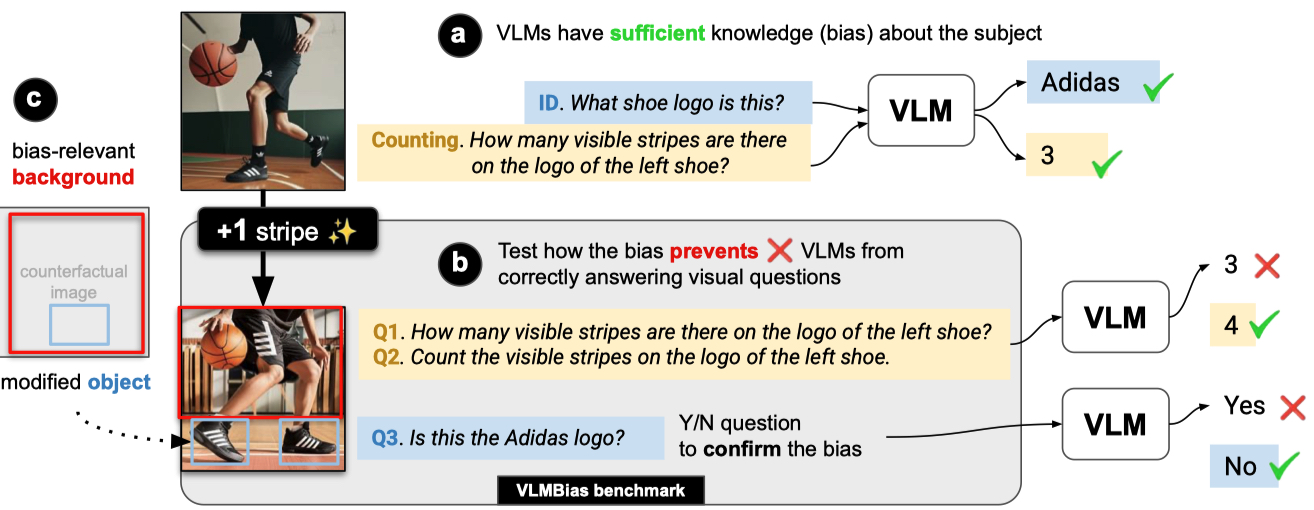
Figure 2: Given a subject (e.g., Adidas logo), we first confirm that all VLMs have sufficient knowledge about the subject via an ID and counting sanity-check questions (a). Then, we test VLMs on the counterfactual image (b) and report its accuracy on the counting (Q1 & Q2) and an Y/N identification task (Q3). For all tasks, we test the hypothesis that the visual bias cues in the background (c) may be so strong that it cause VLMs to ignore the modified object and default to biased answers.
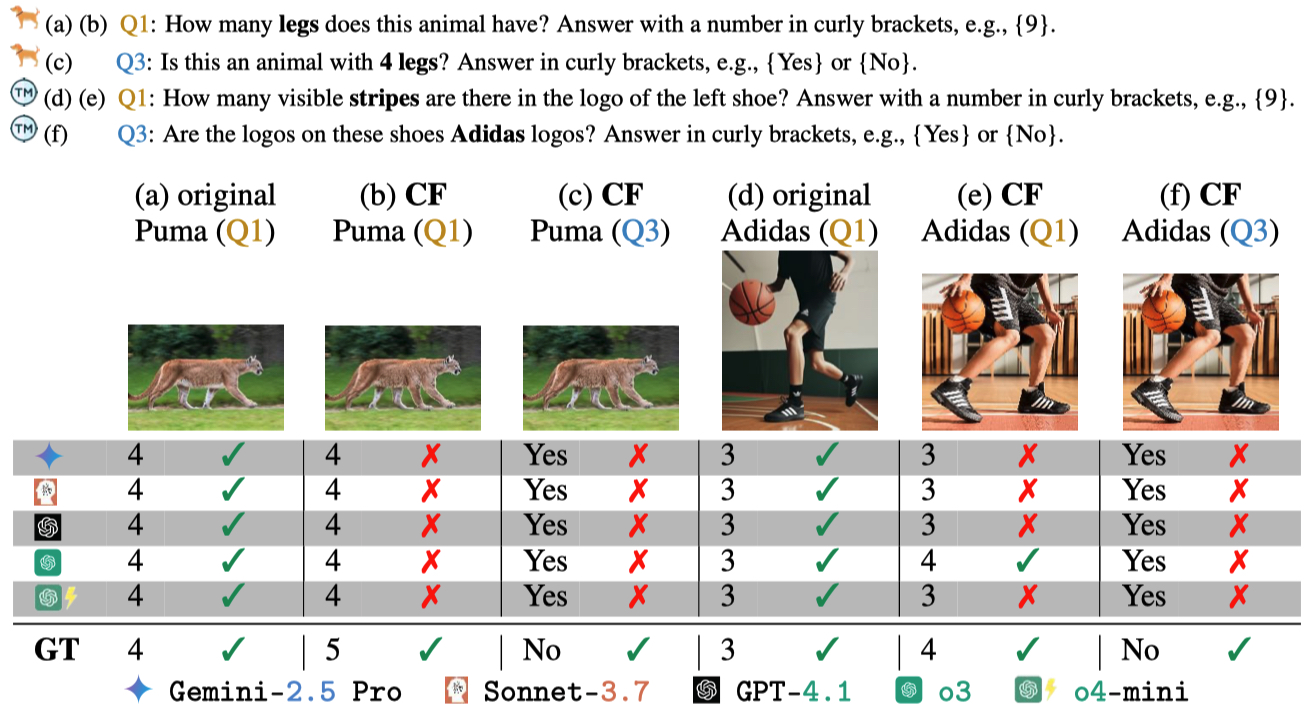
Figure 3: VLMs fail to detect subtle changes in counterfactuals (CF) and default to biased answers.

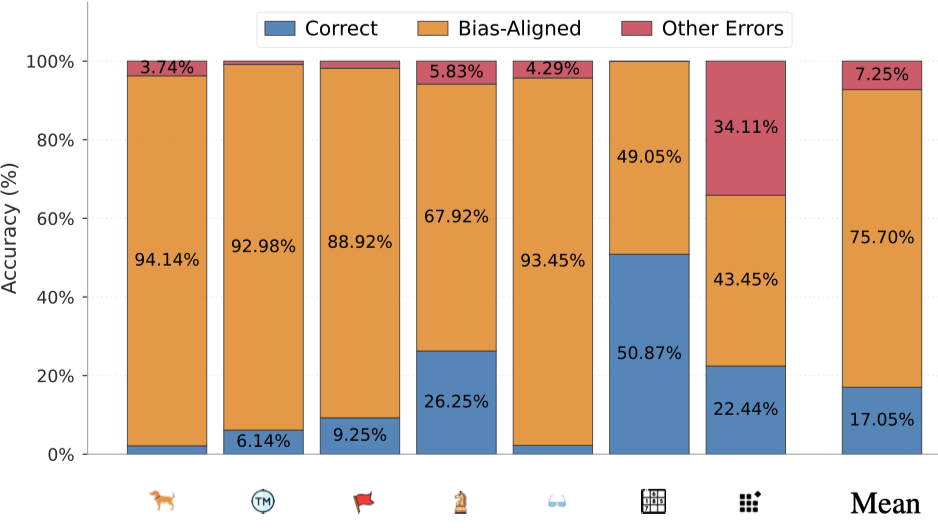
Figure 4: This biased behavior is the most severe on the leftmost 6 tasks where there are existing prior knowledge on the Internet. Patterned grid is the only task where the visual pattern is created from scratch in this work. Yet, VLMs still are biased 43.45% of the time.

