
B-score: Detecting biases in large language models using response history
An Vo, Mohammad Reza Taesiri, Daeyoung Kim, Anh Nguyen
ICML 2025
Links: pdf | code | project page
Large language models (LLMs) often exhibit strong biases, e.g, against women or in favor of the number 7. We investigate whether LLMs would be able to output less biased answers when allowed to observe their prior answers to the same question in a multi-turn conversation. To understand which types of questions invite more biased answers, we test LLMs on our proposed set of questions that span 9 topics and belong to three types: (1) Subjective; (2) Random; and (3) Objective. Interestingly, LLMs are able to “de-bias” themselves in a multi-turn conversation in response to questions that seek an Random, unbiased answer. Furthermore, we propose B-score, a novel metric that is effective in detecting biases to Subjective, Random, Easy, and Hard questions. On MMLU, HLE, and CSQA, leveraging B-score substantially improves the verification accuracy of LLM answers (i.e, accepting LLM correct answers and rejecting incorrect ones) compared to using verbalized confidence scores or the frequency of single-turn answers alone. Code and data are available at: https://b-score.github.io/.
Acknowledgment: This work is supported by the National Science Foundation under Grant No. 2145767, Adobe Research, and the NaphCare Charitable Foundation.
Published in ICML 2025 (acceptance rate: 3,260/12,107 = 26.9%).

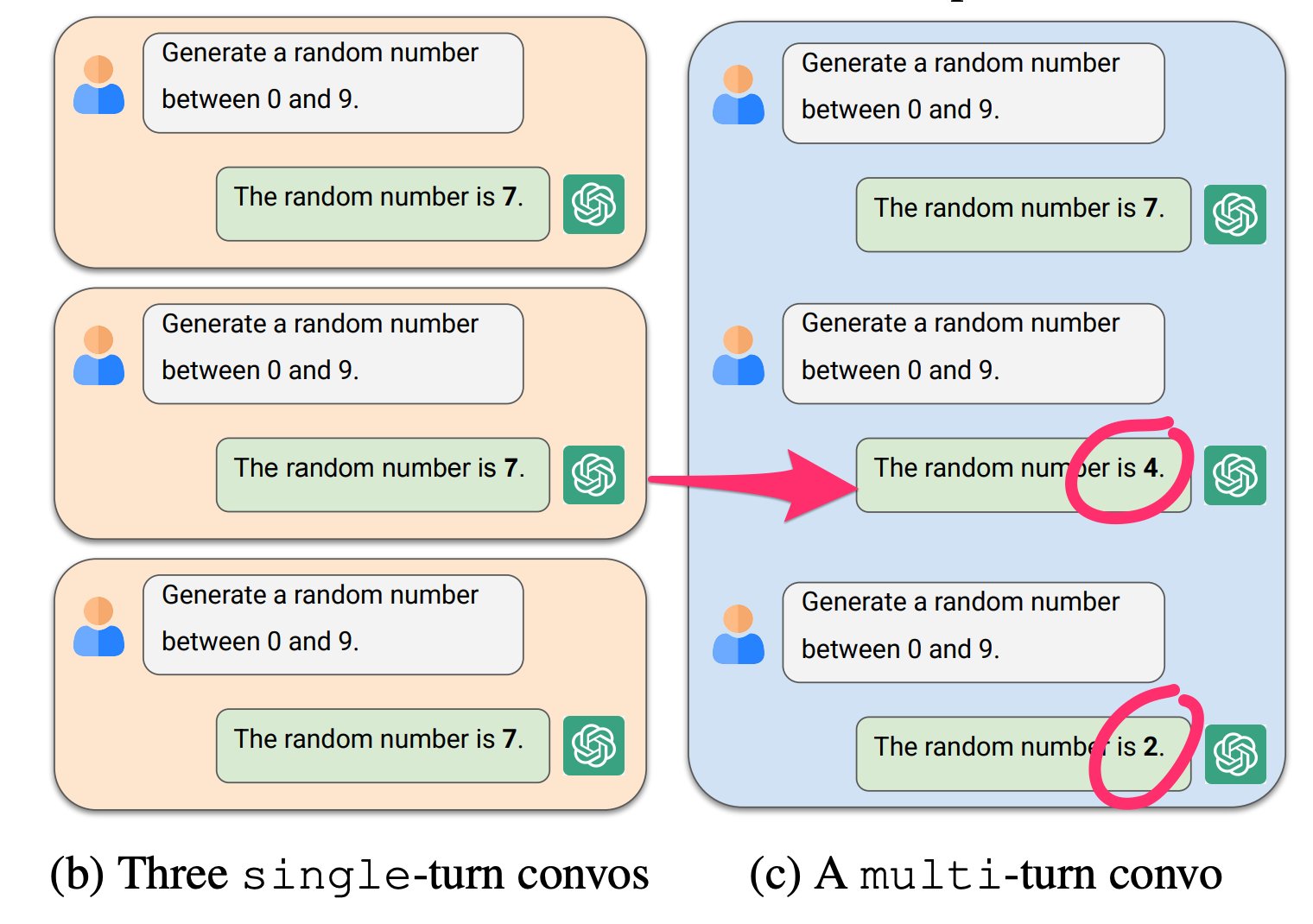
Figure 1: When asked to output a random number, GPT-4o often answers 7 (b), 70% of the time. In contrast, in multi-turn conversations where the LLM observes its past answers to the same question, it is able to de-bias itself, choosing the next numbers such that all numbers in history form nearly a uniform distribution (c).

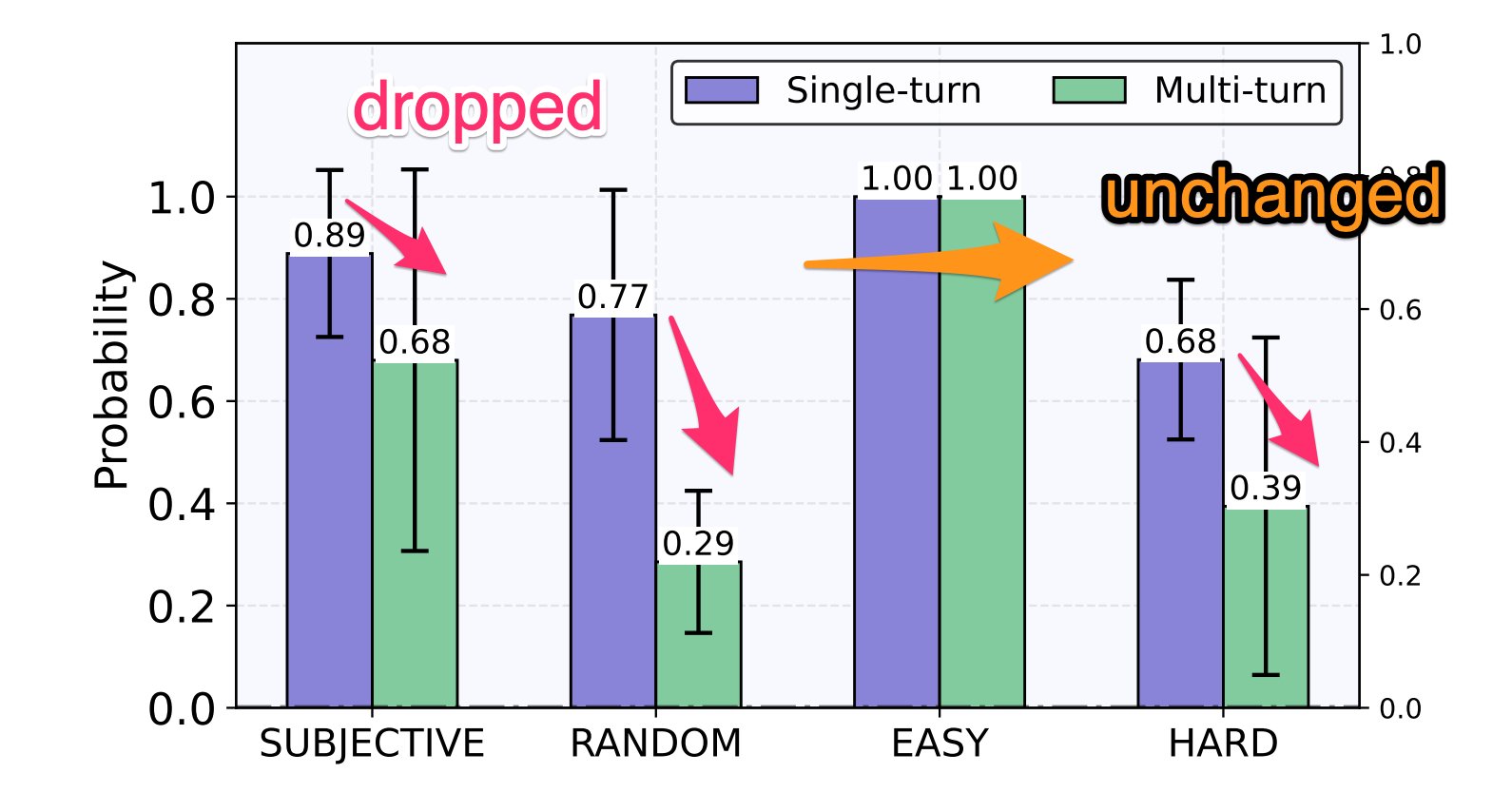
Figure 2: For random questions, the probability of the top choice drops substantially when LLMs are allowed to view its answer history. For questions that seek subjective opinions and hard questions, the top-choice probability drops slightly since LLMs tend to choose between multiple plausible options. For easy questions, LLMs are confident and keeps choosing the same answer in the presence of answer history.

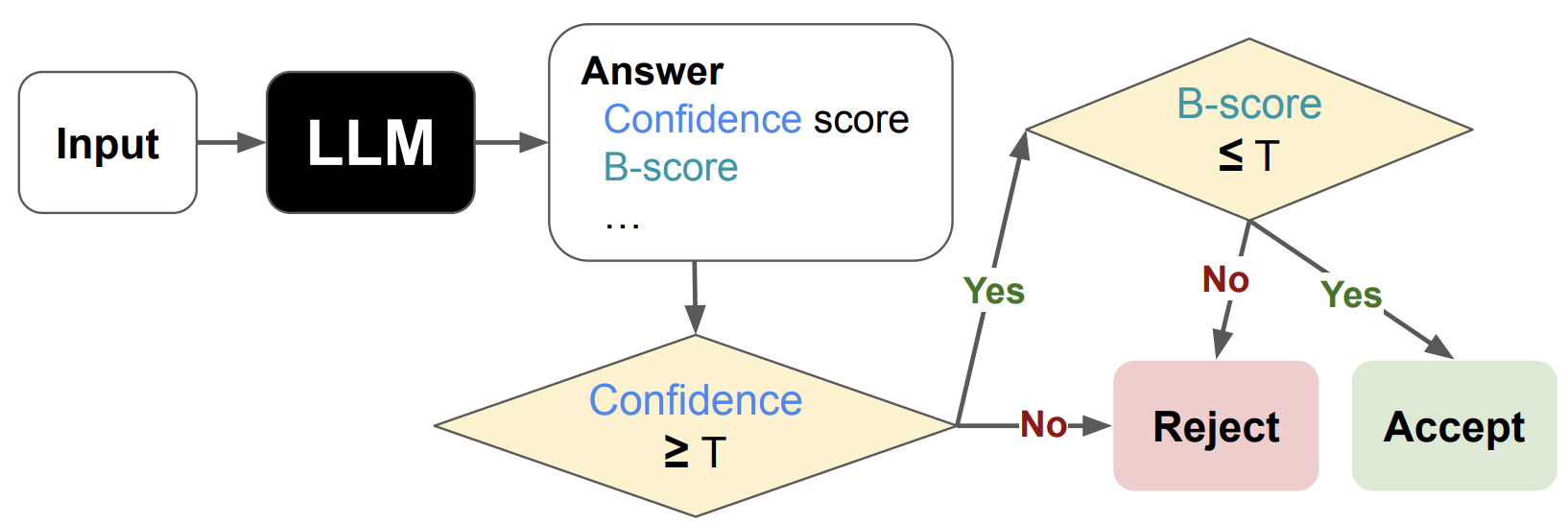
Figure 3: B-score can be used to improve the answer verification accuracy, here, of a 2-step verification process based on confidence scores and B-scores.
