
TAB: Transformer Attention Bottlenecks enable User Intervention and Debugging in Vision-Language Models
Pooyan Rahmanzadehgervi, Hung Huy Nguyen, Rosanne Liu, Long Mai, Anh Totti Nguyen
2025
Links: pdf | code | project page
Multi-head self-attention (MHSA) is a key component of Transformers, a widely popular architecture in both language and vision. Multiple heads intuitively enable different parallel processes over the same input. Yet, they also obscure the attribution of each input patch to the output of a model. We propose a novel 1-head Transformer Attention Bottleneck (TAB) layer, inserted after the traditional MHSA architecture, to serve as an attention bottleneck for interpretability and intervention. Unlike standard self-attention, TAB constrains the total attention over all patches to ∈[0,1]. That is, when the total attention is 0, no visual information is propagated further into the network and the vision-language model (VLM) would default to a generic, image-independent response. To demonstrate the advantages of TAB, we train VLMs with TAB to perform image difference captioning. Over three datasets, our models perform similarly to baseline VLMs in captioning but the bottleneck is superior in localizing changes and in identifying when no changes occur. TAB is the first architecture to enable users to intervene by editing attention, which often produces expected outputs by VLMs.
Acknowledgment: This work is supported by the National Science Foundation under Grant No. 2145767, Adobe Research, and the NaphCare Charitable Foundation.


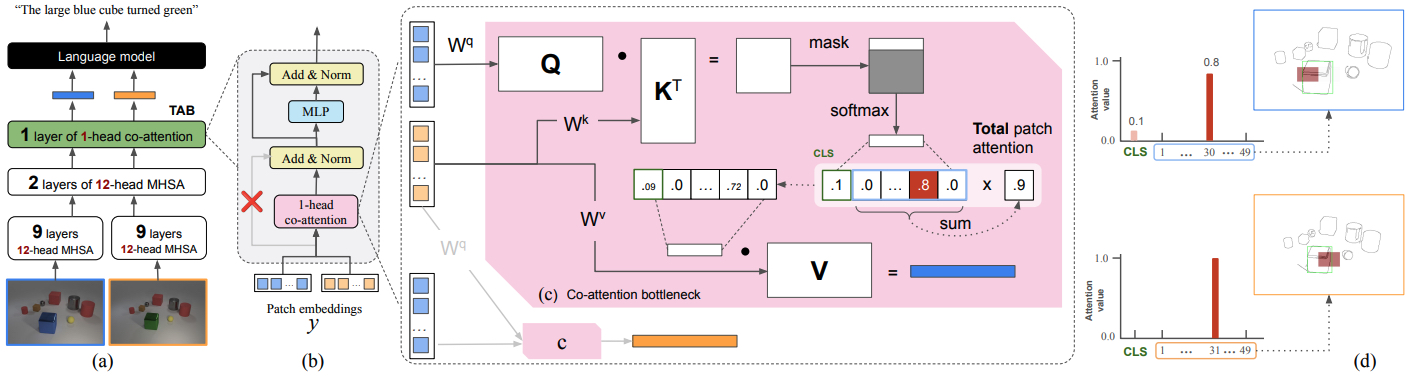
Figure 2: We insert an attention bottleneck (TAB) into a VLM architecture and train it to perform change captioning (a). TAB is a 1-head co-attention [38] Transformer layer (b) that has a skip connection removed so that the 1-head attention (c) serves as an information bottleneck, akin to the forget gate in LSTM, directly controls the visual information that flows into the language model. The attention maps in TAB show precisely how much each patch contributes to the VLM response (d).

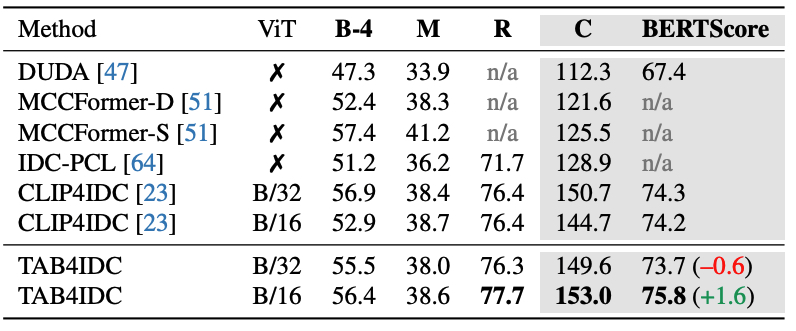
Table 1: Captioning results on CLEVER-Change. TAB4IDC performs better than CC methods that use RNN attention, DUDA [47], and the models that combine CNN and Transformers [51]. Compared to pure Transformer-based VLMs, TAB4IDC is far better than IDC-PCL and on par with its predecessor, CLIP4IDC.

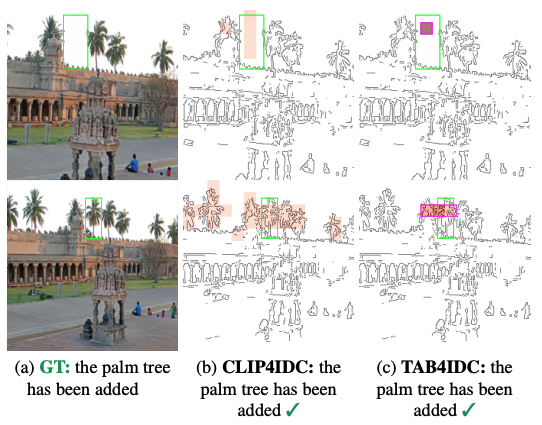
Figure 3: On COCO-Inpainted dataset, the MHSA attention of CLIP4IDC [23] often highlights many patches corresponding to the class name (here, palm tree) in the input image (b). In contrast, TAB points at exactly the only one palm tree that is changed.