Deep neural networks (DNNs) have demonstrated state-of-the-art results on many pattern recognition tasks, especially vision classification problems. Understanding the inner workings of such computational brains is both fascinating basic science that is interesting in its own right – similar to why we study the human brain – and will enable researchers to further improve DNNs. One path to understanding how a neural network functions internally is to study what each of its neurons has learned to detect. One such method is called activation maximization (Erhan et al. 2009), which synthesizes an input (e.g. an image) that highly activates a neuron. Here we dramatically improve the qualitative state of the art of activation maximization by harnessing a powerful, learned prior: a deep generator network (DGN). The algorithm (1) generates qualitatively state-of-the-art synthetic images that look almost real, (2) reveals the features learned by each neuron in an interpretable way, (3) generalizes well to new datasets and somewhat well to different network architectures without requiring the prior to be relearned, and (4) can be considered as a high-quality generative method (in this case, by generating novel, creative, interesting, recognizable images).
Conference: NeurIPS 2016 (23% acceptance rate)
Press coverage:
- The Verge. Artificial intelligence is going to make it easier than ever to fake images and video
- Fast Company. This Neural Network Makes Faces From Scratch (And They’re Terrifying)
- Popular Science. See The Difference One Year Makes In Artificial Intelligence Research
- IFL Science. The “Dreams” Of Artificial Intelligence Are Getting Even More Lifelike
Some people used this method to:
- Synthesize Image Synthesis from Yahoo’s open_nsfw
- Generate music videos
- Visualize features of a net trained on MIT Places 365

Figure 1: Images synthesized from scratch to highly activate output neurons in the CaffeNet deep neural network, which has learned to classify different types of ImageNet images
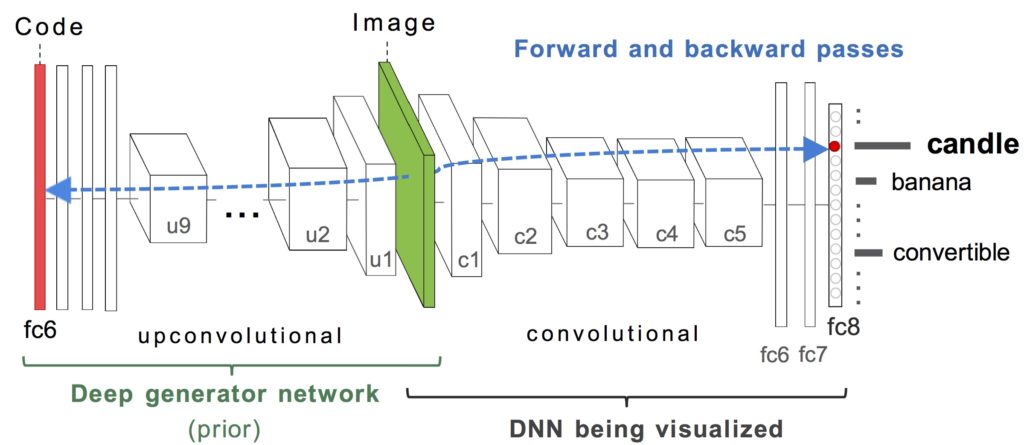
Figure 2: To synthesize a preferred input for a target neuron h (e.g. the “candle” class output neuron), we optimize the hidden code input (red bar) of a deep image generator network (DGN) to produce an image that highly activates h. In the example shown, the DGN is a network trained to invert the feature representations of layer fc6 of CaffeNet. The target DNN being visualized can be a different network (with a different architecture and or trained on different data). The gradient information (blue-dashed line) flows from the layer containing h in the target DNN (here, layer fc8) all the way through the image back to the input code layer of the DGN. Note that both the DGN and target DNN being visualized have fixed parameters, and optimization only changes the DGN input code (red).

Figure 3: Preferred stimuli for output units of an AlexNet DNN trained on the MIT Places 205 dataset, showing that the ImageNet-trained prior generalizes well to a dataset comprised of images of scenes.

Figure 4: Visualizations of optimizing an image that activates two neurons at the same time. Top panel: the visualizations of activating single neurons. Bottom panel: the visualizations of activating “candles” neuron and a corresponding neuron shown in the top panel. In other words, this method can be a novel way for generating art images for the image generation domain, and also can be used to uncover new types of preferred images for a neuron, shedding more light into what it does (here are 27 unique images that activate the same “candles” neuron).

Figure 5: Side-by-side comparison between real and synthesized images. For each neuron, we show the top 9 validation set images that highest activate a given neuron (left) and 9 synthetic images produced by our method (right). For comparison with the results of other image generating models, note that these synthetic images are of size 227×227.

