






The shape and simplicity biases of adversarially robust ImageNet-trained CNNs
Peijie Chen*, Chirag Agarwal*, Anh Nguyen*
Links: pdf | code | project page
* All authors contributed equally.
Adversarial training has been the topic of dozens of studies and a leading method for defending against adversarial attacks. Yet, it remains largely unknown (a) how adversarially-robust ImageNet classifiers (R classifiers) generalize to out-of-distribution examples; and (b) how their generalization capability relates to their hidden representations. In this paper, we perform a thorough, systematic study to answer these two questions across AlexNet, GoogLeNet, and ResNet-50 architectures. We found that while standard ImageNet classifiers have a strong texture bias, their R counterparts rely heavily on shapes. Remarkably, adversarial training induces three simplicity biases into hidden neurons in the process of “robustifying” the network. That is, each convolutional neuron in R networks often changes to detecting (1) pixel-wise smoother patterns i.e. a mechanism that blocks high-frequency noise from passing through the network; (2) more lower-level features i.e. textures and colors (instead of objects); and (3) fewer types of inputs. Our findings reveal the interesting mechanisms that made networks more adversarially robust and also explain some recent findings e.g. why R networks benefit from much larger capacity and can act as a strong image prior in image synthesis.
Acknowledgment: This work is supported by the National Science Foundation under Grant No. 1850117.
4-min Spotlight presentation at the 5th Annual Workshop on Human Interpretability in Machine Learning (WHI 2020)


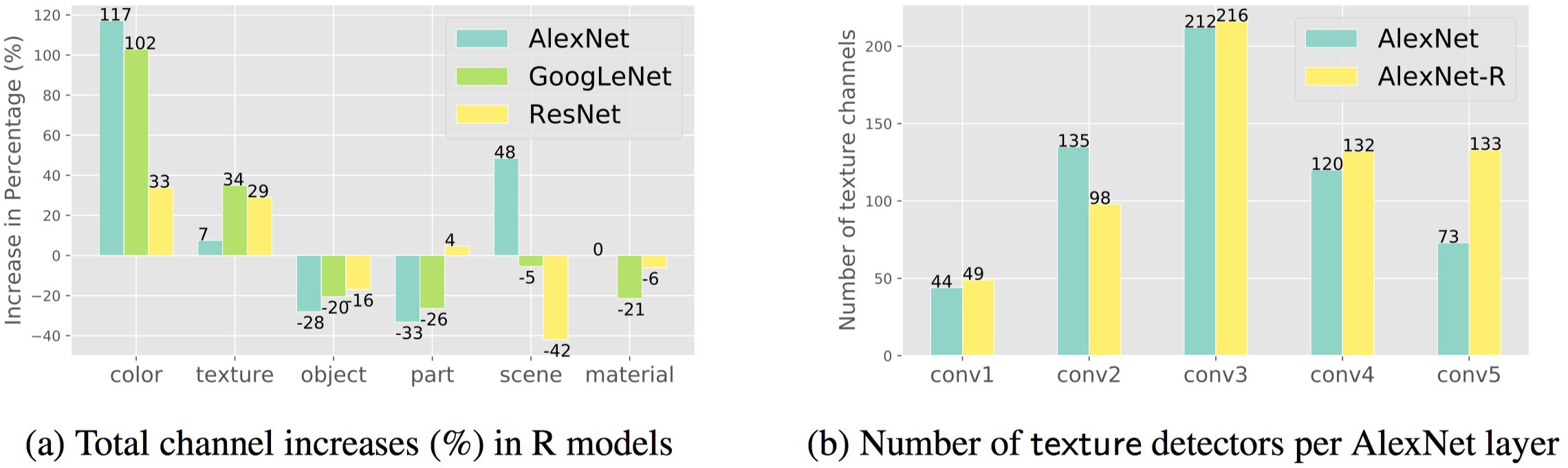
Figure 2: Left: For all three architectures, the numbers of color and texture detectors in R models increase, e.g. by 117% and 7%, respectively, for AlexNet, while the number of object detectors decreases 28%. Right: The gaps between two networks appear larger in higher layers (e.g. 73 → 133 in conv5) than in lower layers (e.g. conv1).

Figure 3: From top to bottom, AlexNet-R (b) preferred consistently simple, homogeneous, patterns, e.g., diagonal edges (conv1), chequered patterns (conv2), crosswords, to dots and net patterns (conv5). In contrast, AlexNet images (a) are much more diverse, including shelves (conv4) and gila monsters in (conv5). Remarkably, the R channels consistently prefer black-and-white patterns in conv2 and conv3 while the standard channels prefer colorful images.

Figure 4: Comparison between the striped neurons (with the highest NetDissect IoU scores) in AlexNet vs. its adversarially-robust counterpart across five main convolutional layers. The striped neurons in adversarially robust AlexNet-R (right) consistently prefer simpler striped patterns than the those in the standard AlexNet.